

2025年11月22日至23日,江苏泰州、河南郑州、浙江义乌三地接连发生火灾,官方通报显示其中两起事故源头直指光伏组件。尤为触目惊心的是,某动物园鸟语林20平米光伏设施的被毁,竟源于一片被引燃的落叶。

从实验室报告到户外实证,全行业共同见证
频发的火灾事故,让光伏组件安全性再度成为全行业关注的焦点。11月28日,来自产业链各环节的代表——包括电站业主、经销商、技术专家和权威媒体,再次齐聚银川国家光伏质检中心(CPVT)全球最大的户外实证基地。他们的目标明确而一致:共同见证两个月前隆基获颁的行业首张"三防"检测证书,能否经得起实证的严苛检验,以及其在真实环境下的性能表现到底怎么样。

"报告再漂亮,不如实地看一看。"隆基分布式中国区总裁牛燕燕的开场致辞,为这场实证活动定下了务实基调。她强调,在光伏行业面临挑战的当下,隆基选择用创新回应质疑,用实证建立信任。而这一次的完全透明,就是从"发布现场"到"实证现场"的深度求证。
实证的价值需要时间验证。24年10月,隆基与CPVT邀请国内二十余家权威媒体和光伏行业大V,亲手搭建了一座小型的实证电站,经历一年运行后,其组件依然保持着稳定发电状态。对比平均单块直流累计发电量,TOPCon组件样品平均发电908度,而BC组件样品平均发电965度,有近6.3%的增益提升。

国家太阳能光伏产品质量检验检测中心的刘毅部长,在现场阐释了三防组件认证体系的严谨性与权威性。
"作为经国家市场监管总局批准的第三方检测机构,CPVT不仅基于常规IEC标准进行检测,更构建了"实验室检测+户外实证"的双重验证体系。"刘毅强调。目前CPVT在全国建立了12个户外实证基地,涵盖沙戈荒、生态修复、冰雪基地和深蓝海洋等不同应用场景,以确保检测结果能够真实反映组件在各种复杂环境下的实际表现。
CPVT正将其深厚的实验室检测能力,持续转化为对三防组件检测方案的引领。其关键举措之一,在于主导制定了IEC63556标准——这是中国在IEC体系内突破的首个环境大类标准,目前已完成CD稿投票,标志着草案获国际专家初步共识,进入下一制定阶段,迈向全球统一规范的关键里程碑。

所有的理论与认证,最终都指向一个核心问题:三防组件在严苛的真实环境中,究竟能否兑现其安全与高效的承诺?实证数据给出了清晰的答案。
三大防护维度,如何重新定义安全边界
鸡蛋实验背后,是169℃与97℃的安全鸿沟
安全不是多与少的问题,而是有和无的问题。如果说光伏电站收益是“100”的话,收益都是后面的0,只有安全才是这个最开始的1。安全出问题,不仅所有发电收益归零,更可能引发人员伤亡等沉重代价。
安全,正是BC技术的核心优势之一。
在众多见证者的注视下,实验室温度对比实测展现出了惊人差异:
1000W/m²辐照光源下,对比遮挡电池整片的1/4,三防组件稳定后温度为97.1℃,而TOPCon组件温度高达169.1℃。这一温差在实际演示中更为直观:同时在两块组件热点区域敲碎生鸡蛋,一方在滋啦声中迅速凝固变白;而三防组件上的蛋液仍基本保持全生状态。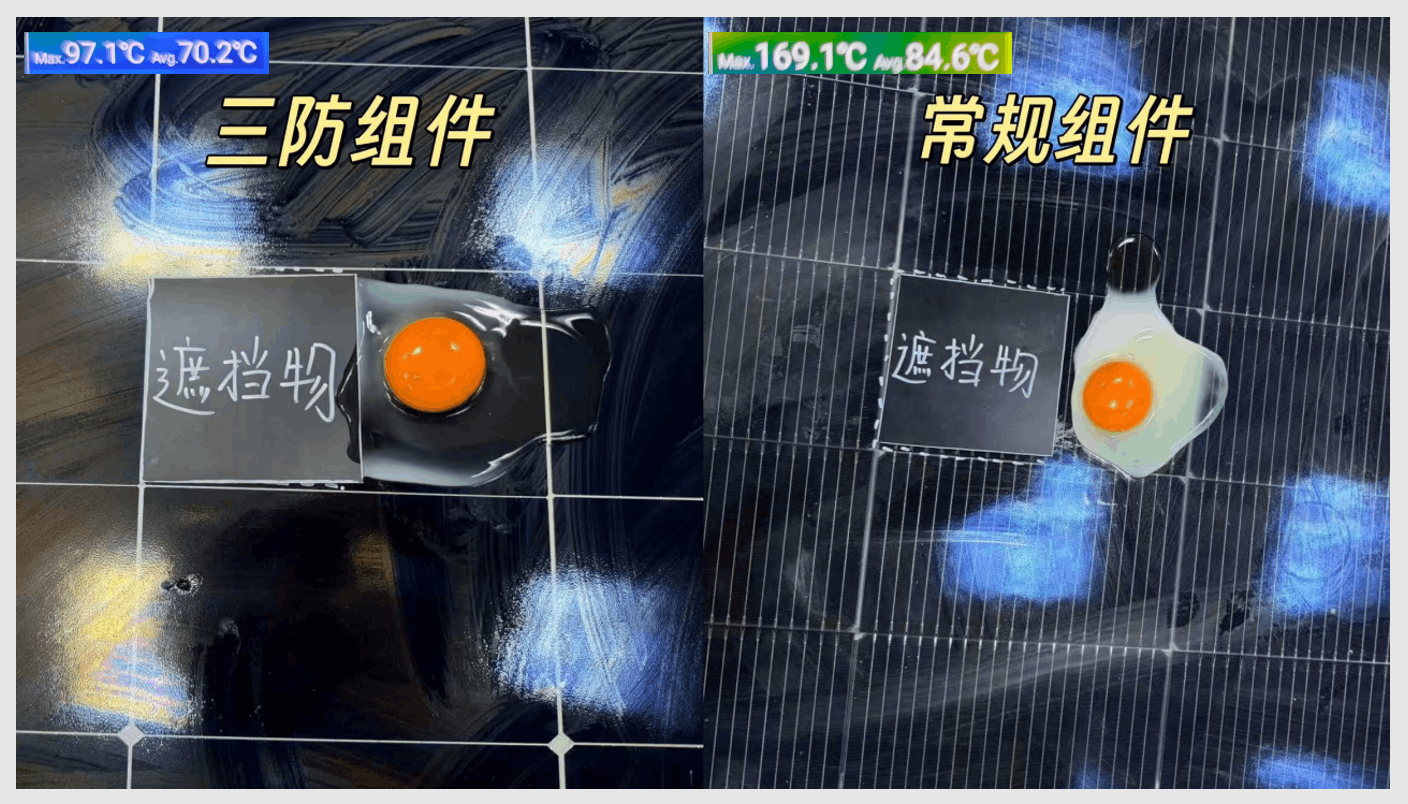
一位资深电站业主在亲眼目睹后表示:“这不仅是数据差异,更是投资安全的保障。”
不久前刚落幕的2025全球BC技术创新峰会上,隆基BC组件荣获由TÜV莱茵认证的“组件级抗起火风险认可证书”。不仅再次印证了三防组件的防起火性能,同时意味着自光伏组件问世60年来一直被困扰的起火问题得到了有效规避,客户提出的新质量要求得到了明确回应。
破解“木桶效应”,遮挡场景发电增益最高达50%
如果说防火是安全的底线,那么在复杂遮挡环境下保持稳定发电,则直接决定系统的实际收益。
女儿墙遮挡场景
实证数据显示,从10月初到11月中旬,三防组件对比TOPCon累计单瓦发电增益高出1.91%,单位面积发电增益高出6.85%。这说明,三防组件在面对“横向带状”遮挡时具备更大发电优势。这一优势也直接转化为经济效益——1MW电站BC组件较TOPCon一年少损失发电收益1.183万元。
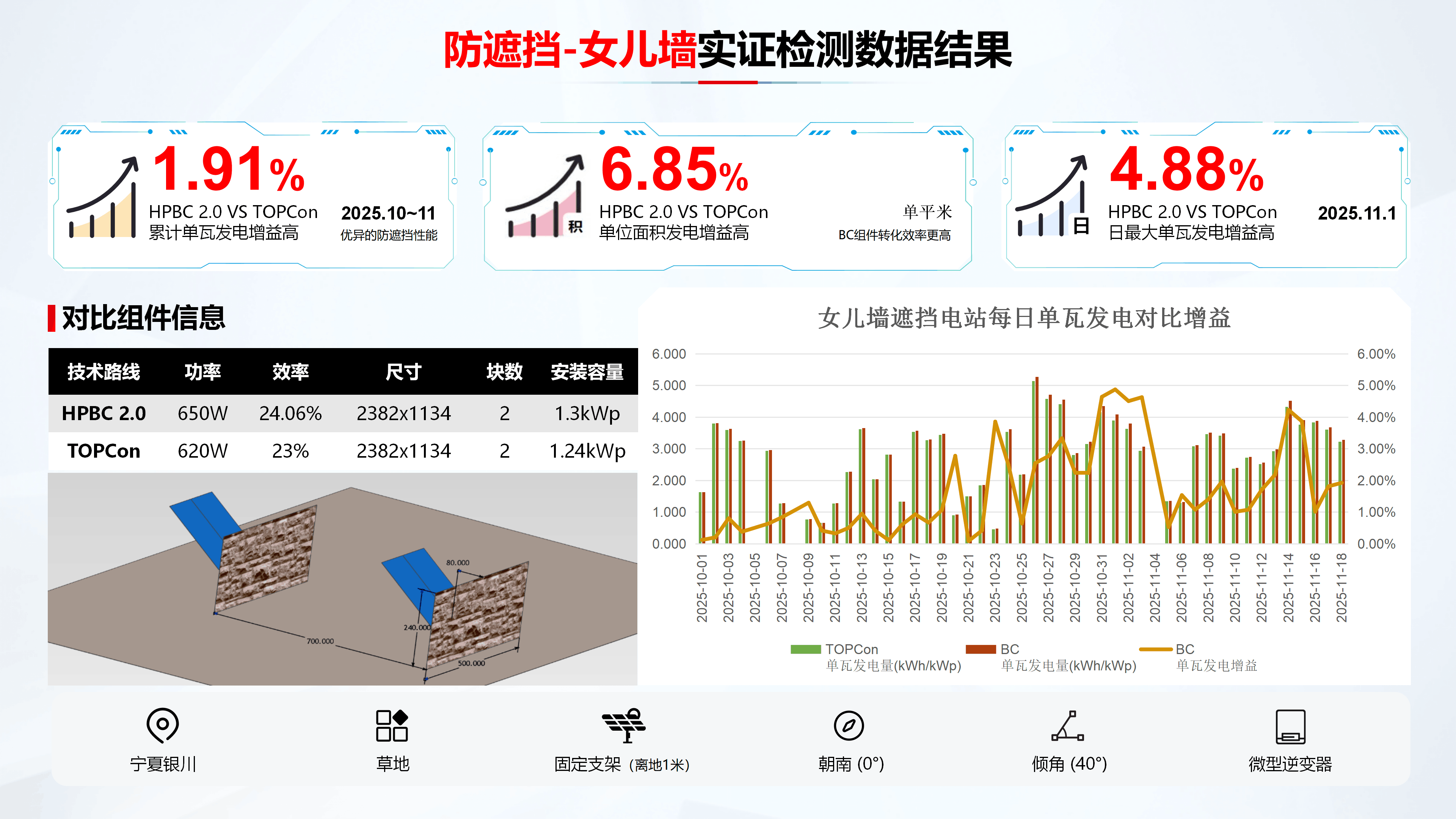
区别于CPVT单片实证,屋顶工商业电站通常以组串形式接入逆变器。福建某电站女儿墙遮挡验证显示:整串BC组件较TOPCon实际单瓦超发2.55%,显著高于单块组件数据。
“这背后的原因是‘木桶效应’。”隆基分布式业务中国区产品解决方案负责人郭晋维解释道,“整串运行中,电流受限于最弱环节,一块TOPCon组件被遮挡就会导致整串发电量断崖式下跌。”
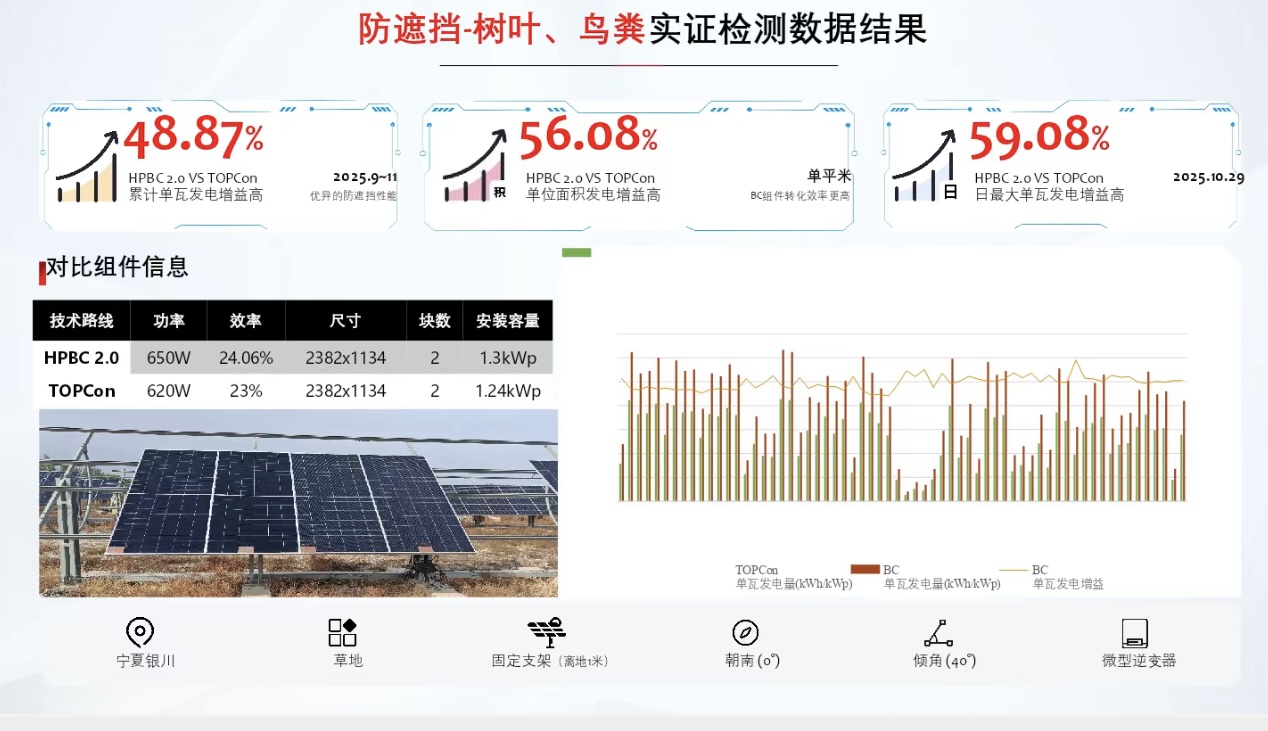
树叶遮挡场景
该场景模拟的是如树叶、鸟粪等常见“点状“静态遮挡,差距更为显著:单瓦发电增益高出TOPCon组件48.87%,单位面积发电增益高出56.08%。这意味着长期遮挡情况下1MW电站一年可少损失发电收益28.908万元。而组串的实际应用增益在海南三亚实证基地更为明显,整串组件相较于TOPCon的实际超发比例更是达到50.92%。
电线杆动态遮挡
为模拟屋顶常见设备(如电线杆、热水器、空调外机、换气风机等)随日光移动投射的动态阴影,现场采用电线杆这一“竖向”遮挡进行模拟。结果显示三防组件单瓦发电增益高出2.49%。而鉴衡认证的组串级实证显示,这一优势在真实电站中更加明显——BC组件较TOPCon单瓦超发11.34%,1MW电站一年少损失约7.23万元。

其技术根源,在于隆基HPBC2.0组件独有的电池片级旁路二极管设计。该设计可在遭遇遮挡时迅速启动,将影响精准隔离在局部,从而保证未遮挡区域正常发电,而这一优势是TOPCon技术所不具备的。
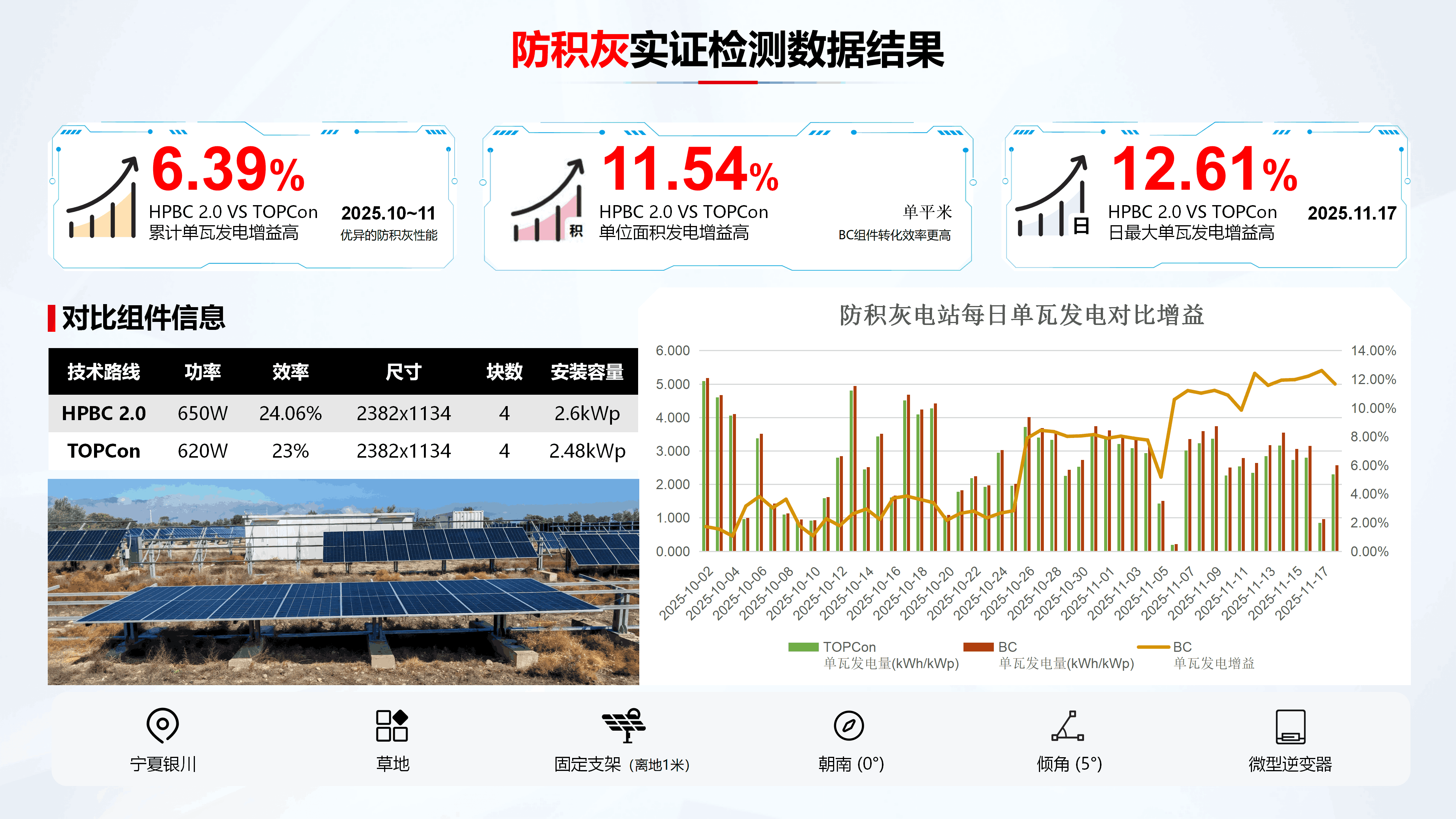
短边平齐边框设计,带来6.39%的发电增益
积灰是分布式光伏,尤其是彩钢瓦屋面小倾角安装场景下的普遍痛点。在本次银川实证现场,这一问题在西北干旱少雨、风沙频繁的气候条件下被放大得尤为明显。现场对比可见,传统组件下沿已形成深色积灰带,而隆基三防组件凭借独特的边框设计,表面积灰得到显著控制。

“这得益于我们对组件短边边框的创新设计。”郭晋维展示了产品细节,“常规短边边框A面高出组件上表面2-5mm,而隆基防积灰组件短边A面与组件上表面保持平齐,使灰尘更易被雨水、大风冲刷。”
这一看似微小的改进,却带来了显著的额外增益。实证数据显示,在5度安装倾角下,三防组件对比传统TOPCon组件单瓦发电增益高出6.39%,单位面积增益达11.54%。而日单瓦发电增益随着积灰日积月累,呈明显上升趋势,于统计截点日达到顶峰,对比高出12.61%。这意味着1兆瓦电站每年可减少损失,约3.84万元的发电收益,且在提升发电效率的同时,更大幅降低了运维清洗频次与成本。
以实证建立信任,用创新跳出内卷
随着最后一项测试数据在现场大屏定格,这场历时一天的严苛实证画上圆满句号。隆基三防组件在防火、防遮挡、防积灰三大维度的表现,不仅验证了行业首张证书的含金量,更赢得了市场的直接认可。
事实是最有力的证明:即便三防组件的价格较主流Topcon产品高出了0.1元/w,但在隆基分布式业务中的销售占比已快速攀升至70%以上,市场的需求强劲。
市场的选择印证了一个根本逻辑:安全是所有发电收益的前提。隆基通过技术创新筑牢安全防线,让三防组件超越了单纯的价格竞争,实现了从“发电单元”到“安全系统”的价值升级。这不仅是产品的胜利,更是发展理念的突破——唯有立足客户真实需求,以科技构建核心壁垒,才能带领行业跳出内卷,行稳致远。

 电话:
电话: 传真:
传真: 邮箱:
邮箱: 地址:
地址: